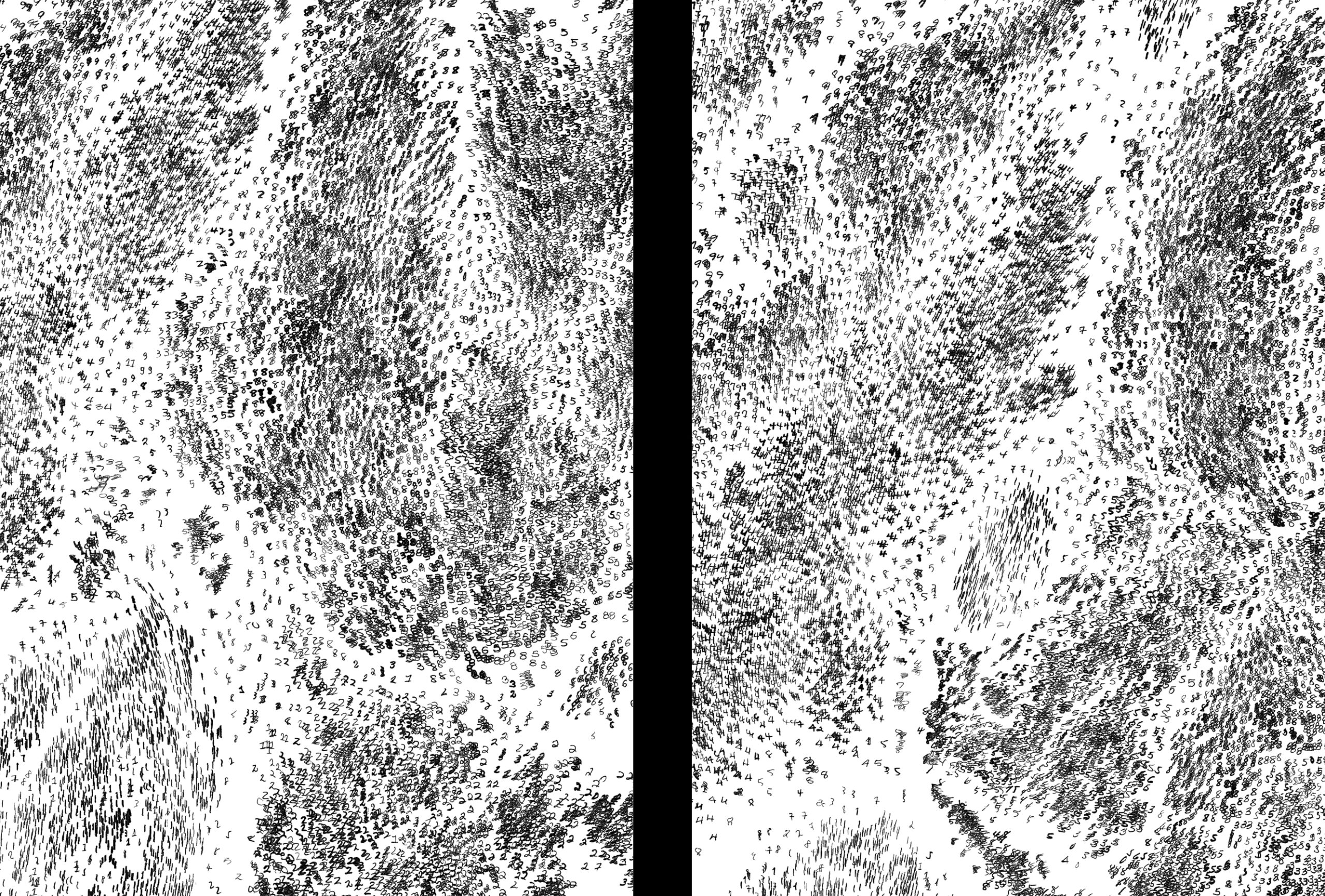
There are only few applications in artificial intelligence research as pivotal as the classification of handwritten digits. It has become a classic in the field to apply the MNIST dataset of handwritten digits to any machine learning algorithm and architecture, old and new, in order to derive preliminary estimates of their efficacy. While the task of optical character recognition is considered to be solved, it serves as a good example to highlight the uncertainty of any automated classification application.
For this edition of 30 prints (and three artist proofs), 70.000 handwritten digits were classified, clustered, and deliberately mapped onto the image surface according to their similarity and ambiguity. Derived by an algorithm which clusters digits based on their shape and probabilistic functions, the final arrangement differs from one print to another. While some false classifications creep up on their fringes, otherwise neatly clustered packs of digits are seen divided by organic ridges.